Enhance the quality of your API calls with Client-Side Throttling
Oct 2, 2016If you are a backend engineer and work with high load environment you should be familiarized with the old Server-Side Rate Limit, mainly for security concerns.
Didn’t you ever heard about Server-Side Rate Limit? It is a technique to limit the amount of requests that the server or API can handle in a defined period of time, and that limit can be set per user or not.
Throttling is often used to limiting traffic on the server, mainly as a way to protect against DOS Attack. Additionally, it can also be used on the client-side, as this article describes.
When a rate limit is exceeded, all requests are throttled and fail for a brief period of time or until the activities back to normal. Once throttled, the caller usually get the HTTP 403 (forbidden) status as response.
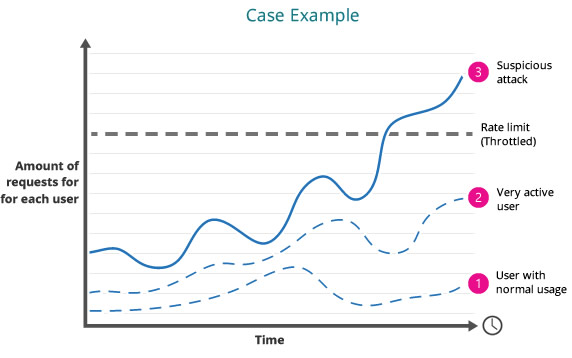
In the above picture, the user #3 are exceeding the global or individual rate limiting, being throttled to guarantee the quality of service and security.
Just reject the requests is enough?
When a user is throttled, his next requests calls will be rejected. This behavior consumes significantly fewer resources than actually processing the requests and serving back correct responses.
If a request were simple, like only retrieving information from local memory, it is almost equally expensive to reject it as it is to accept it and return the expected result.
Additionally, we should consider that the server also allocates resources to receive the requests, establishing a complete TCP connection to finally reject them. Helping DDoS attackers.
Big mistake when consuming APIs.
Consider that you are creating the new version of Facebook client, that makes periodics requests to Facebook API to collect news feed, comments, likes, online users etc.
Almost everytime happens that unprepared clients, once throttled and getting rejected requests from API, keep making the same amount of requests, trying to reach the data.
As result, the API keep blocking the user to maintain the overall quality of the service and your client could never retrieve the data as desired.
How to apply Client-Side Throttling with Adaptive Throttling?
When a client detects that a significant portion of its recent requests have been rejected, it starts self-regulating and caps the amount of outgoing traffic it generates.
Requests above the cap should fail locally without even reaching the network.
Adaptive throttling is the key to solve the problem. To implement this technique the client needs to keep the following information for at least two minutes of its history:
- Requests: The number of requests attempted by the application.
- Accepts: The number of requests accepted by the backend.
When everything is fine at the client, the two values are equal. Once the API start rejecting the client requests the number of Accepts becomes smaller than the number of Requests.
The client app should still be able to issue requests to the API until the Requests be K times grather than Accepts, assuming K > 1.
For example, K = 1.1 means that the client will allow one Reject for each 10 Accepts.
Once the threshold is surpassed, which will happen when the state of the system meet the criteria Requests > k * Accepts, the app should be able to self-regulate and new requests are now reject locally based on the probability P0 described below.

Example, the client app performed 1000 Requests in the last 2 minutes, with 600 of them Accepted. Also, our system is designed to allow 4 rejects for each 10 requests which means that our K = 1.4.
In the previous scenario the app should start regulating new request based on P0 since the initial criteria is meet:

Since the client app is issuing more requests than our sample K allow, the app should reject new requests locally to the server with probability equal to 0.16, rejecting 16 requests in 100:
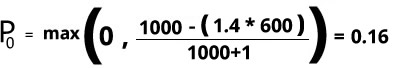
The problem with that approach
The P0 probability is originally defined in the Chapter 21 of the book Site Reliability Engineering: How Google Runs Production Systems by, guess who? Google guys.
The main goal is to increase the probability of dropping new requests, as soon as the server appears to be overloaded (assuming a small value of K). Doing this, every client instance will help the server recover faster from the outage, by using less resources.
Also, this approach is used in some Google services and they suggest K = 2, based on their own experiences.
My concerns about this probability is that, if the server goes down for more than 2 minutes, the P0 value will stand in 1, rejecting locally every new request to the server, so the client app won’t be able to set up a new conection. As the result of it, the client app will never have another request reaching the server.
I would like to suggest a new probability measure, P1, that upper limits the chance of rejecting a new request to 90%, allowing the client to recover even in that worst scenario, when the service is down more than 2 minutes.
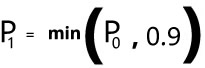
I have noted that this technique can benefit client libraries and apps to enhance their own quality. Also, companies that offer comunication through APIs, in order to improve their own quality, should encourage client designers to use techniques like these.
Cheers,
Rafael.